heap sort 使用了 heap 來幫助我們做sort 的工作
時間複雜度為 O(n logn)
為穩定排序法
核心概念為運用heap 的特性
假設我們有一個 size 為 n 的 heap
每次將root 與heap 的最後一個位置交換
然後再執行一次 size 為 n-1 的 heapify()
重複此動作直至所有元素都被排序完為止
在實作的部分
我們習慣將存data 的陣列的第0個位置空出來
從第1個位置開始存
這樣才能符合 heap 的特性
heap sort 使用了 heap 來幫助我們做sort 的工作
時間複雜度為 O(n logn)
為穩定排序法
核心概念為運用heap 的特性
假設我們有一個 size 為 n 的 heap
每次將root 與heap 的最後一個位置交換
然後再執行一次 size 為 n-1 的 heapify()
重複此動作直至所有元素都被排序完為止
在實作的部分
我們習慣將存data 的陣列的第0個位置空出來
從第1個位置開始存
這樣才能符合 heap 的特性
bubble sort 是一種 internal sort
適合資料量小或已經有初步排序的資料使用
其 worst case 為 O(n^2)
如果是要由小排到大
核心概念是由前往後兩兩比對,若前者大於後者則交換
並由較大者繼續與後面的元素兩兩比對。
每scan一次能確定一個元素的最後位置
在改良版的bubble sort 裡加入了 flag 來判斷該次 scan 有沒有做 swap
如果沒有則不需要額外的 scan
linear search 是一個最簡單的搜尋方法
又稱為 sequential search
其搜尋方式就是從頭搜到尾
worst case 的時間複雜度為 O(n)
interpolation search 為 binary search 的改良版
適合用在資料平均分佈的狀況下
其內插法公式為
mid = low + ((key – data[low]) / (data[high] – data[low])) * (high – low)
而其餘的搜尋步驟則與 binary search 差不多
平均而言其時間複雜度優於 O(log n)
fibonacci search 跟 binary search 一樣都是使用二分法來進行切割範圍和搜尋
不同的是 fibonacci 是用 fibonacci number 來切割
也就是說我們會先建立一個 fibonacci tree
然後再依照此 tree 來做search
示意圖 – 來源
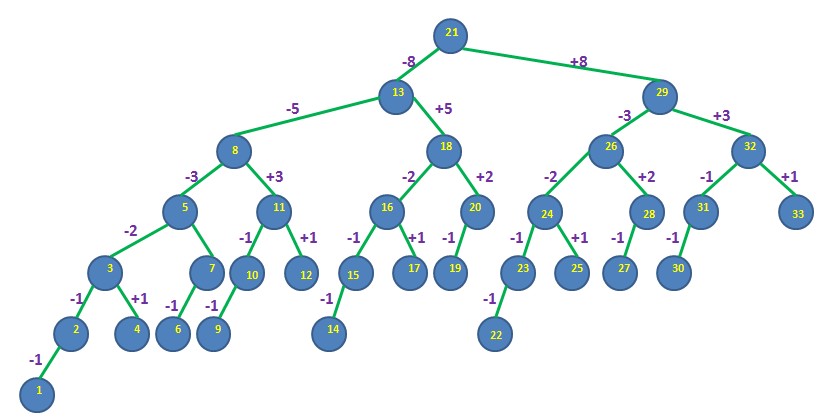
fibonacci tree 的 root 是由資料個數 n 決定的
先利用 Fib(k+1) >= n + 1
來決定 k
再以Fib(k) 當作root 的值
而其左子樹為 (k – 1) 階Fibonacci tree
右子樹為 (k-2) 階 Fibonacci tree
依此類推可以建立完整的 Fibonacci tree
更多詳細資料可參考 – 程式扎記
binary search 是一種用於事先排序好的資料的搜尋演算法
算是 divide and conquer 的變形 (少了 merge 的步驟)
核心概念於訂定三個 index : low, mid, high
如果要找的 key 大於 data[mid], 則搜尋右半邊
如果小於 data[mid] 則搜尋左半邊
否則回傳mid 的位置
一直找下去
如果 high < low 則代表找尋不到
因其每次可以prune 掉一半的資料
所以其時間複雜度為 O(n log n)
Retext 是一個好用的 Markdown 編輯器
支援同步瀏覽
內建 apt-get 所安裝的版本是2.0
如果要安裝 4.0的話
安裝方式如下
sudo add-apt-repository ppa:mitya57
sudo apt-get update
sudo apt-get install retext
如果是 ubuntu 12.04 安裝的話會有 dependency
可以用 aptitude 來解決缺少python3-pyqt4的問題
aptitude 會提供幾種策略解決,在筆者的環境是先按 N 再按 Y
使用第二種策略才解決成功
參考來源:ReText 3.0 Released (Text Editor For Markdown And reStructuredText)
安裝好之後 Retext 本身對於 markdown 的 css 跟 github 上差很多
所以要做以下設定
vim ~/.config/ReText Project/ReText.conf
[General]
useReST=false
defaultExt=md
useWebkit=true
styleSheet=/home/自己的家目錄/.config/ReText project/github.css
github.css 可以到 github.css 下載
如此就可以得到支援 github css 格式的 markdownn編輯器
參考來源:配置Retext
令 N = 2^n
在一個 size 為 N x N 的二維空間中
Hilbert curve 會遞迴地將我們的空間切成四個相同size 的 blocks
而每一個 block 我們都會給一個 0 ~ N^2 -1 的number
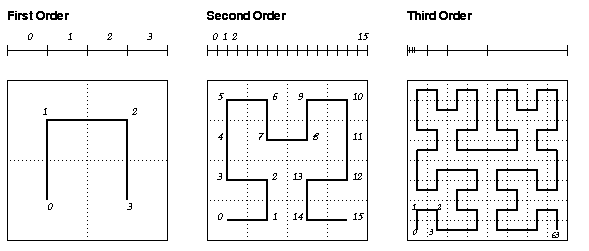
舉例來說
order n = 1 時我們可以得到一串分別是 0 ~ 3 的數字
而 order n = 2 則是由 order n = 1 演化而來
只要將order n = 1 的第一個 block 與最後一個 block 做 reflection 跟 rotation 即可得到結果
依此類推
order n = 3 是由 order n = 2 演化而來, 做的是相似的 reflection 與 rotation
一個空間上的物件可以是任意形狀
而通常我們會取一個 bounding rectangle 來表示這個物件
而坐標可利用 Xl, Xr, Yb, Yt四個屬性來定義
在此我們用 L(Xl,Yb) 與 U(Xr,Yt) 來表示一個物件
在 Bucket Number Scheme 裡面我們將一個 Bucket 以 0 或 1 來表示
也稱作 DZ expression
表示的規則有兩點:
在x軸中的0表示左半部, 1表示右半步。而在y軸中0表示下半部, 1表示上半部
越左邊的bit 代表越前面的binary division, 越後面的bit 代表越裡面的division
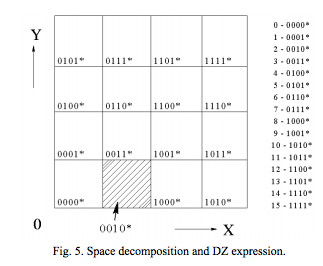
以圖中的例子
舉例來說 0010* 表示的是
00代表的是整個區塊裡面的左半部及下半部
10代表的是左半部及下半部中,右半部及下半部
以此類推。
而在此我們也會使用 Max_bucket 來記錄所有bucket 中最大的 bucket number

在 Fig.6(a) 中我們將 binary form 轉成 decimal form
而在 Fig.6(b) 中我們可以依照順序劃線來得到 N-order peano curve
Pelican 是一個 python 寫的 static site generator
可以將產出的網頁放到 github page 上
安裝過程可參考 Installing Pelican
在此紀錄幾個重要的步驟
安裝 pelican sudo pip install pelican
安裝 Markdown sudo pip install markdown
安裝 ghp-import sudo pip install ghp-import
接著就可以下 pelican-quickstart 來自動產生資料夾